HiveMQ Edge 2025.4 is Released
What’s new in HiveMQ Edge 2025.4
HiveMQ Edge just got even better at handling and transforming your data. With our new Data Combiner you can now bring OT and MQTT data sources together into unified MQTT topics, making it easier to work with mixed data streams. On top of that we’ve also added Stateful Transformation capabilities via Data Hub, giving you more options to normalise and clean your data at the edge.
These new features build on HiveMQ Edge’s existing tools to make managing and governing your edge data more straightforward than ever. Whether you're dealing with complex systems or just need a better way to organise your data, HiveMQ Edge has you covered. Keep reading to find out how these updates can help streamline your operations.
To make it even easier to deploy and configure HiveMQ Edge, we’ve introduced several powerful updates to our Helm charts.
Data Combining
How it works
The Data Combiner can combine multiple OPC-UA tag and MQTT topic filter sources together in a single MQTT topic to publish from HiveMQ Edge, the following steps demonstrate how to do this via the Edge Console.
In this example we’ve created two OPC-UA adapters, monitoring temperature sensors across two floors in a manufacturing environment.
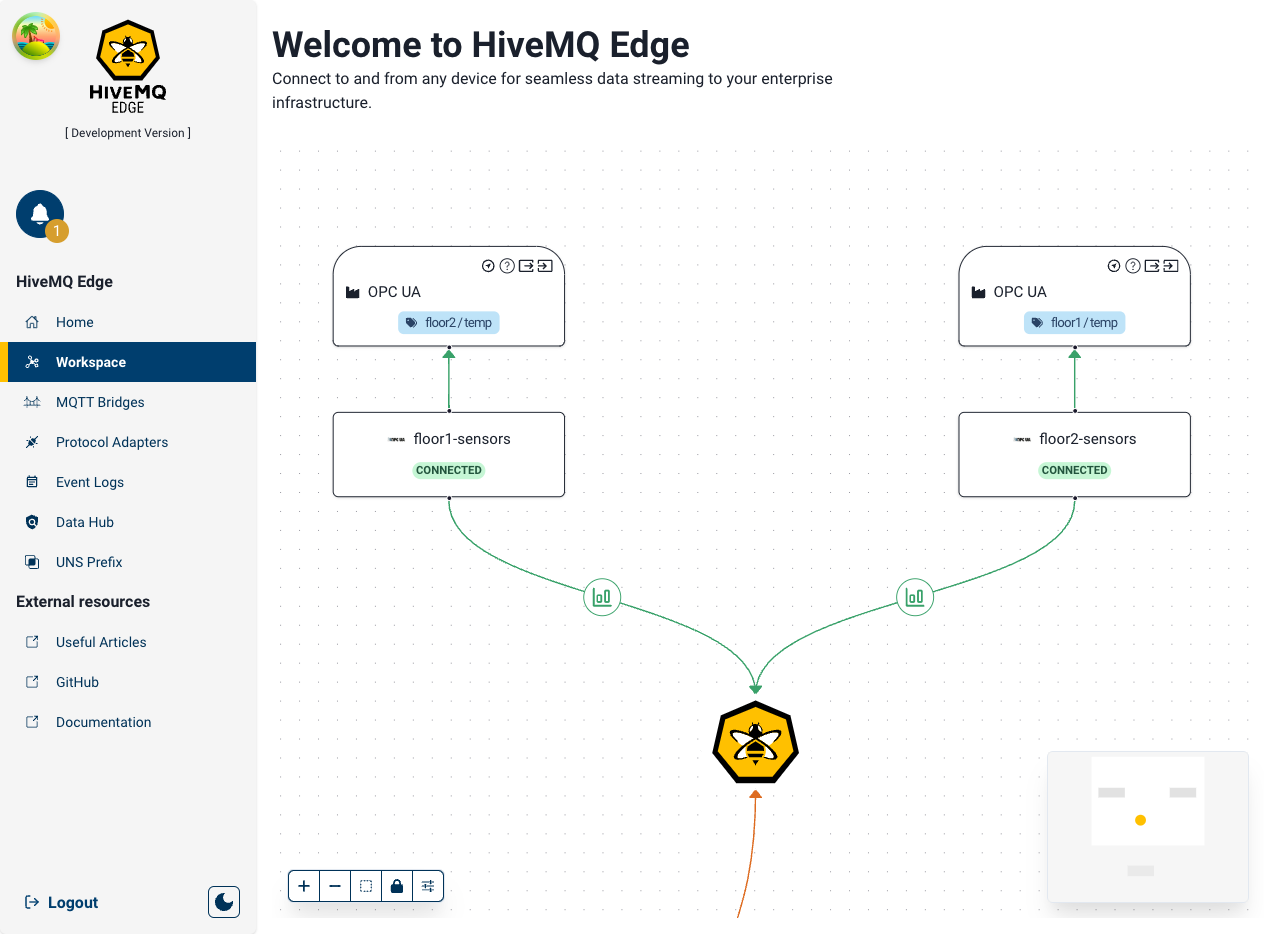
We map temperature tags on each floor’s OPC-UA endpoint.
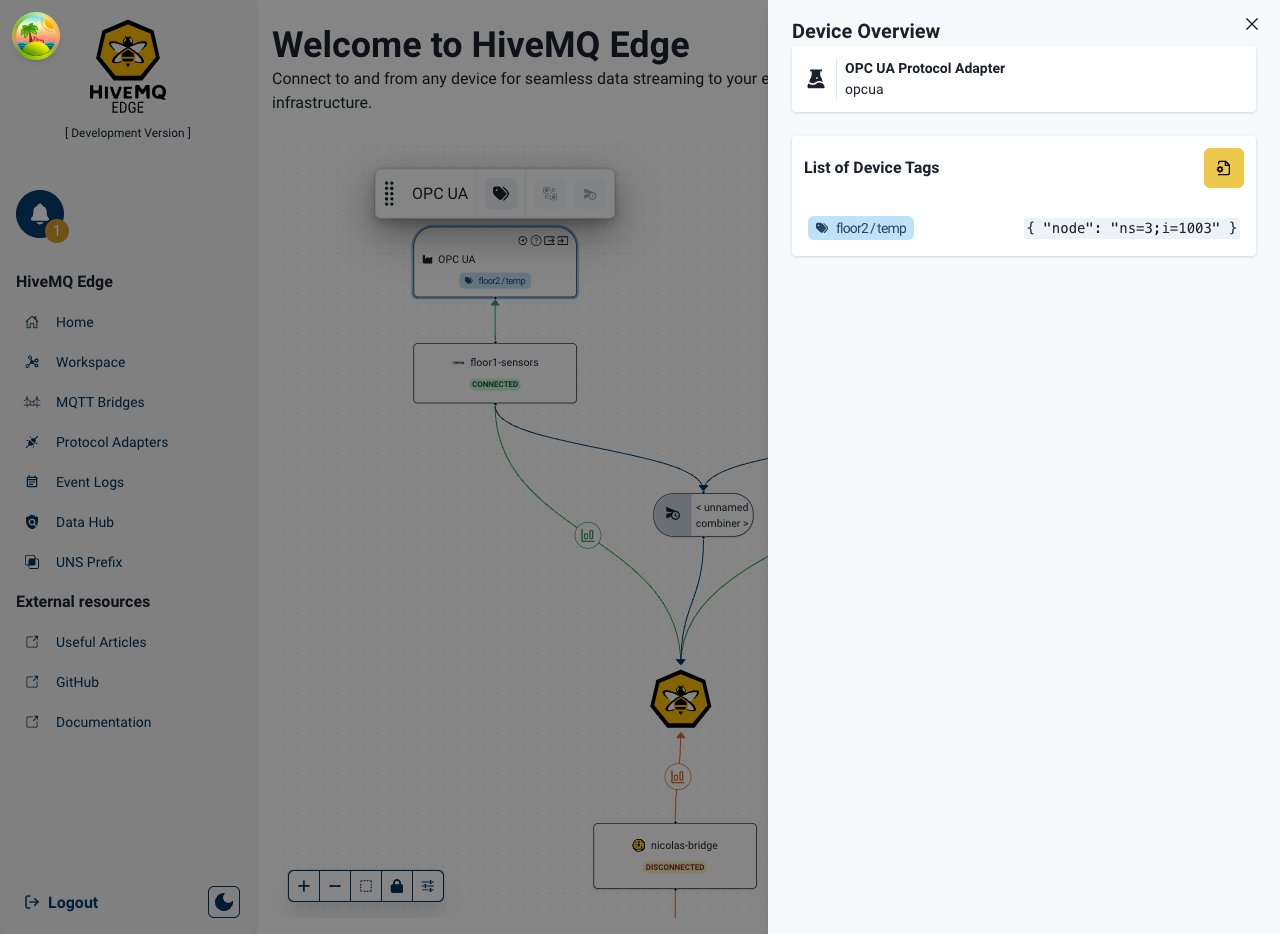
To create a combiner, we initially select the sources where the data we wish to combine from exist (in this case the two OPC-UA adapters).
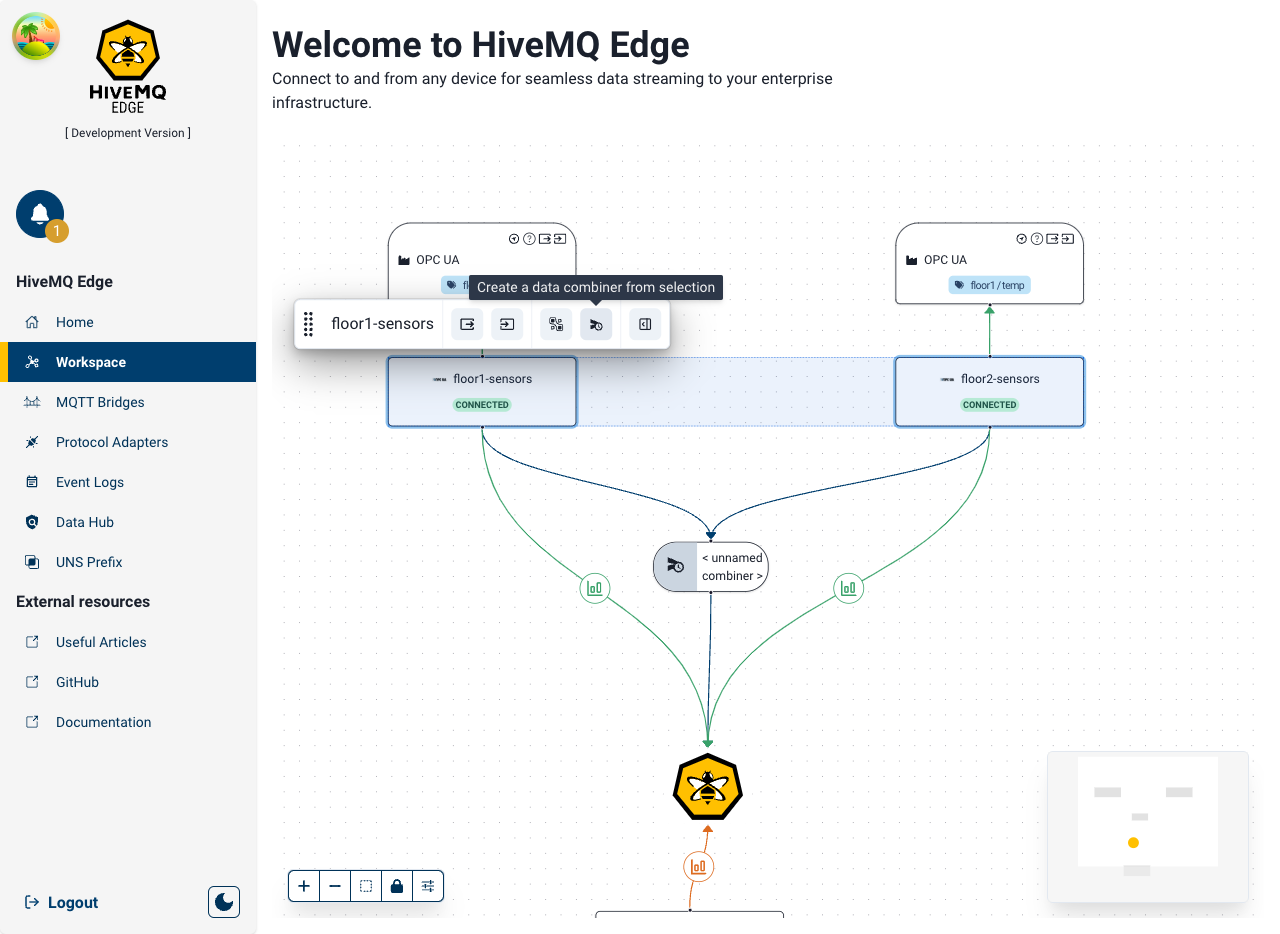
A combiner node can now be created on the Workspace, using the sub menu as shown above, connecting both adapters (as source) and the Edge node (as the target).
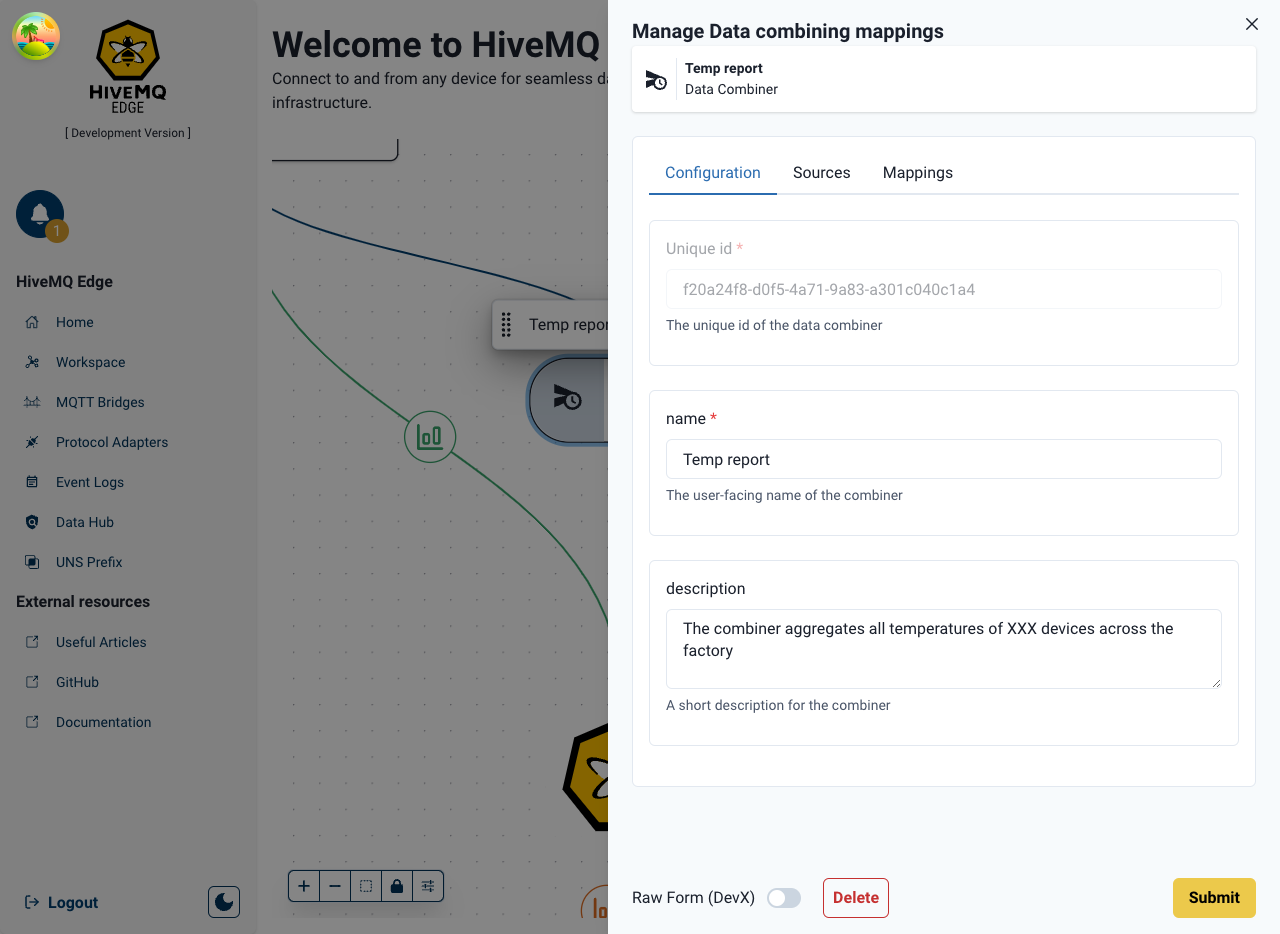
Double-clicking on the Combiner node opens the configuration panel
- The name and the description of the newly created combiner can be modified to provide a human readable identifier
- The list of sources can also be managed directly in the configuration
- Data mappings can now be created to derive the exact data the user wants to take from each source
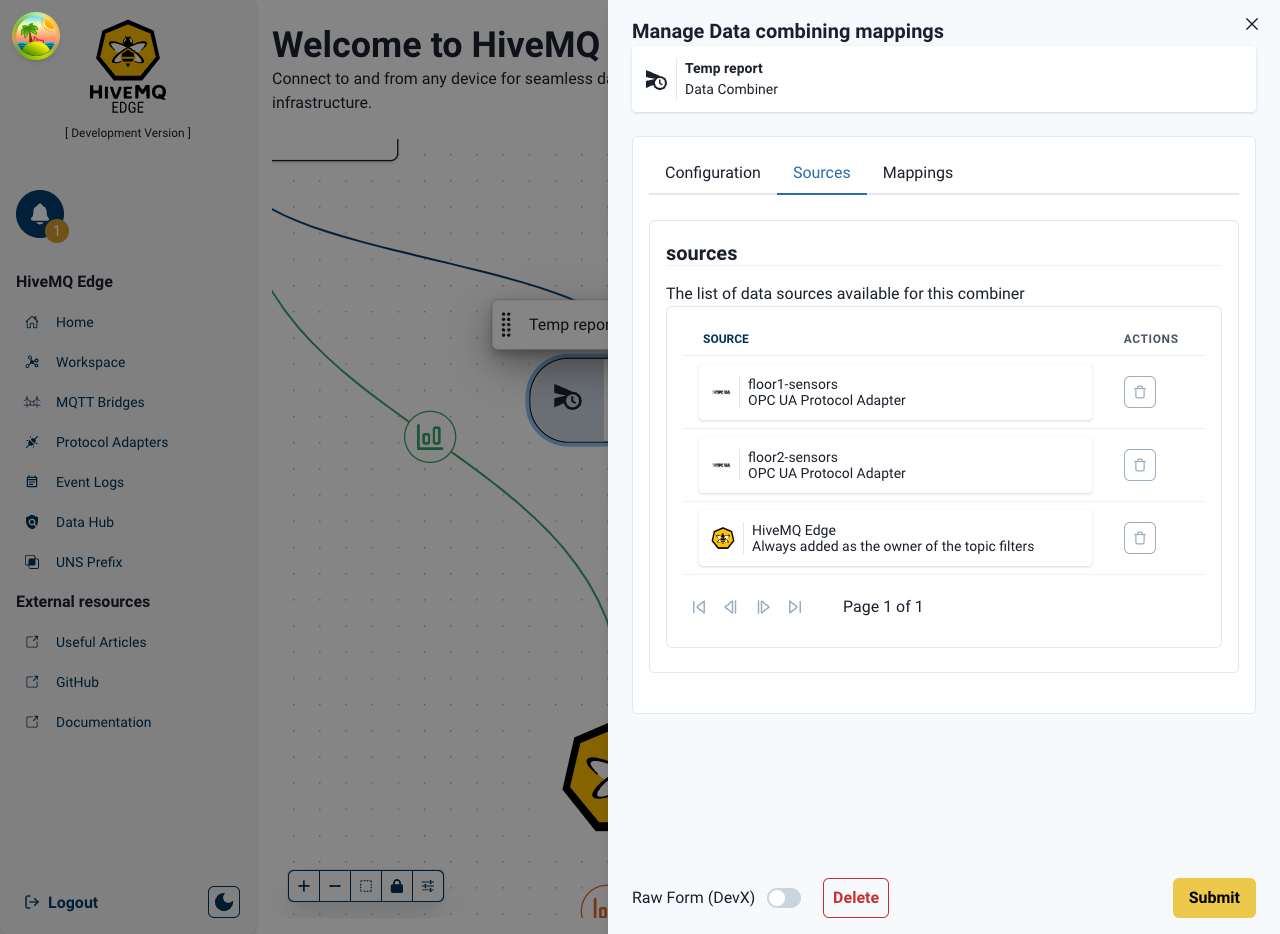
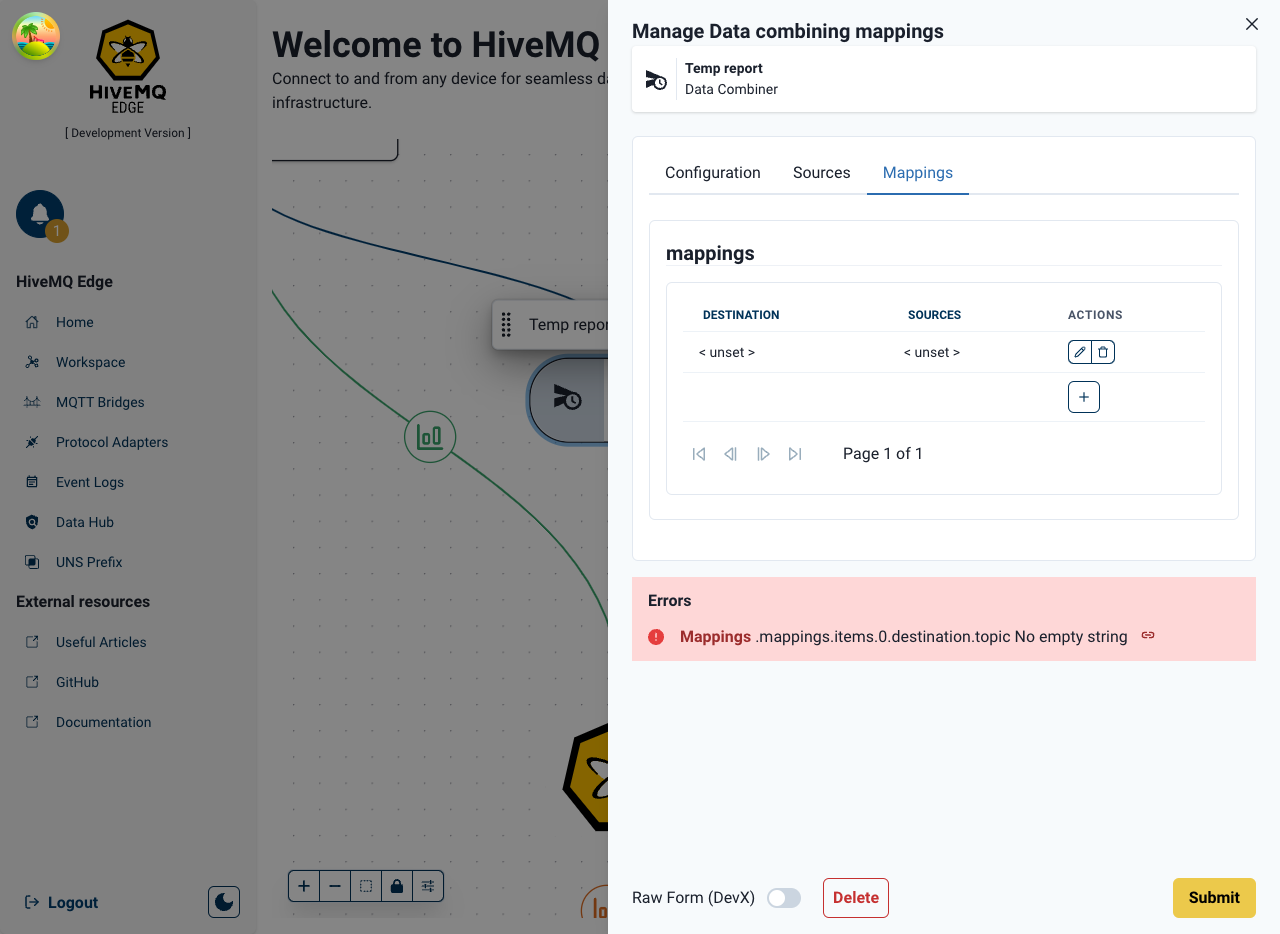
Multiple data Mappings for the same sources can be created, and they are edited via the click of the pencil icon which opens up a separate configuration interface.
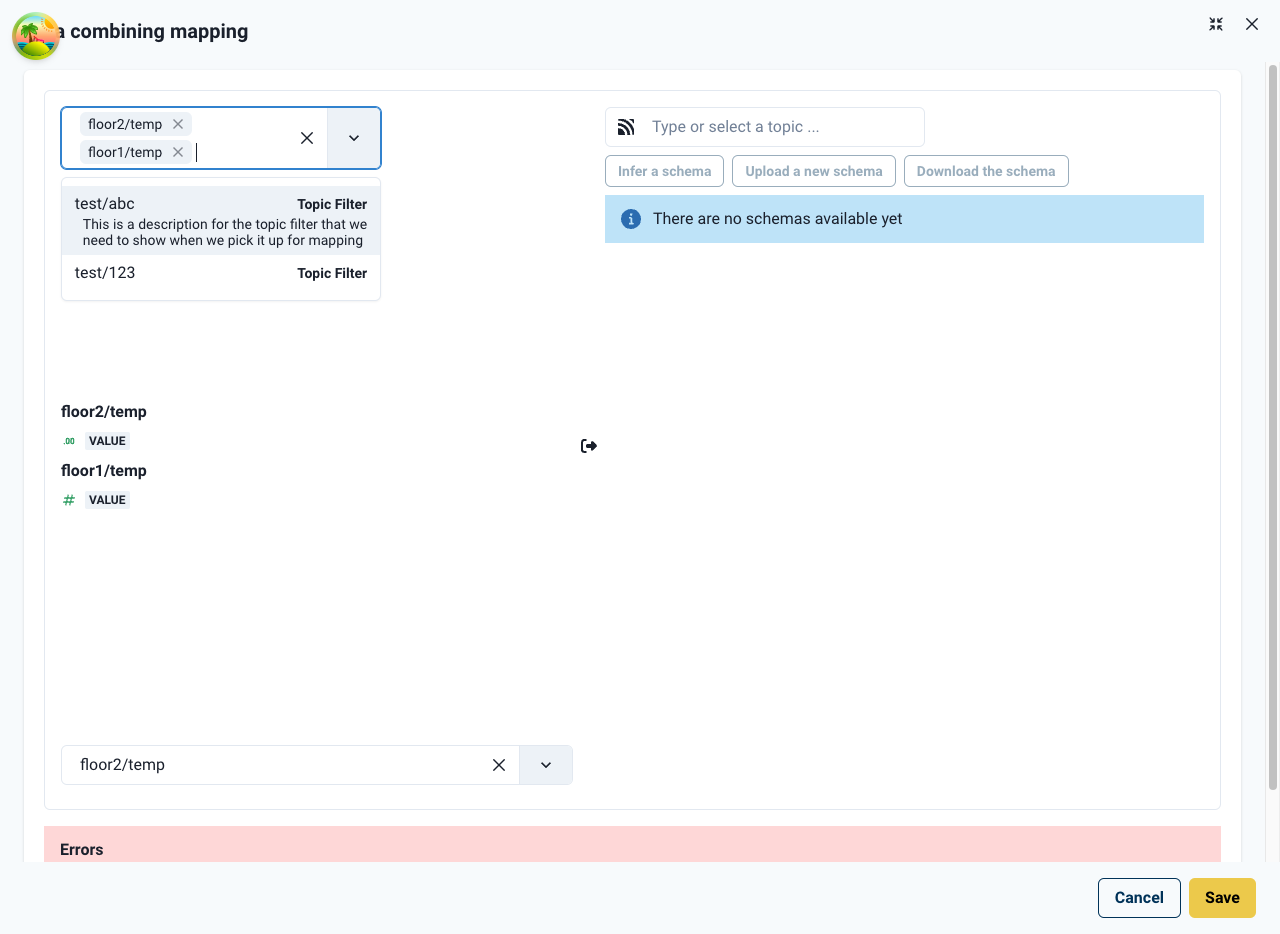
In the combination mapper interface the left-hand side of the dialog:
- Select the tags (and / or topic filters) that you want to combine as a northbound MQTT topic
- Selected tags will be then displayed below in a list, accompanied by their data schema (automatically generated from the PLC configuration)
- One of these tags must be selected as a primary key for the combination (see below)
On the right-hand side of the mapper interface, focuses on the destination topic:
- Create a new topic via the topic field, or select an existing one via the drop down presented
- Upload a new schema that describes the payload you are expecting for the topic
For example, we are using the following JSON-Schema
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "All temperature sensors from building 1",
"type": "object",
"properties": {
"report": {
"type": "object",
"required": ["floor1", "floor2"],
"properties": {
"floor1": {
"type": "number"
},
"floor2": {
"type": "number"
}
}
}
},
"required": ["report"]
}
The schema is rendered on the combination mapping panel as a series of properties, to be mapped with values from the source schemas. In this example we drag value from floor1/temp into report.floor1 and repeat the process for floor2.
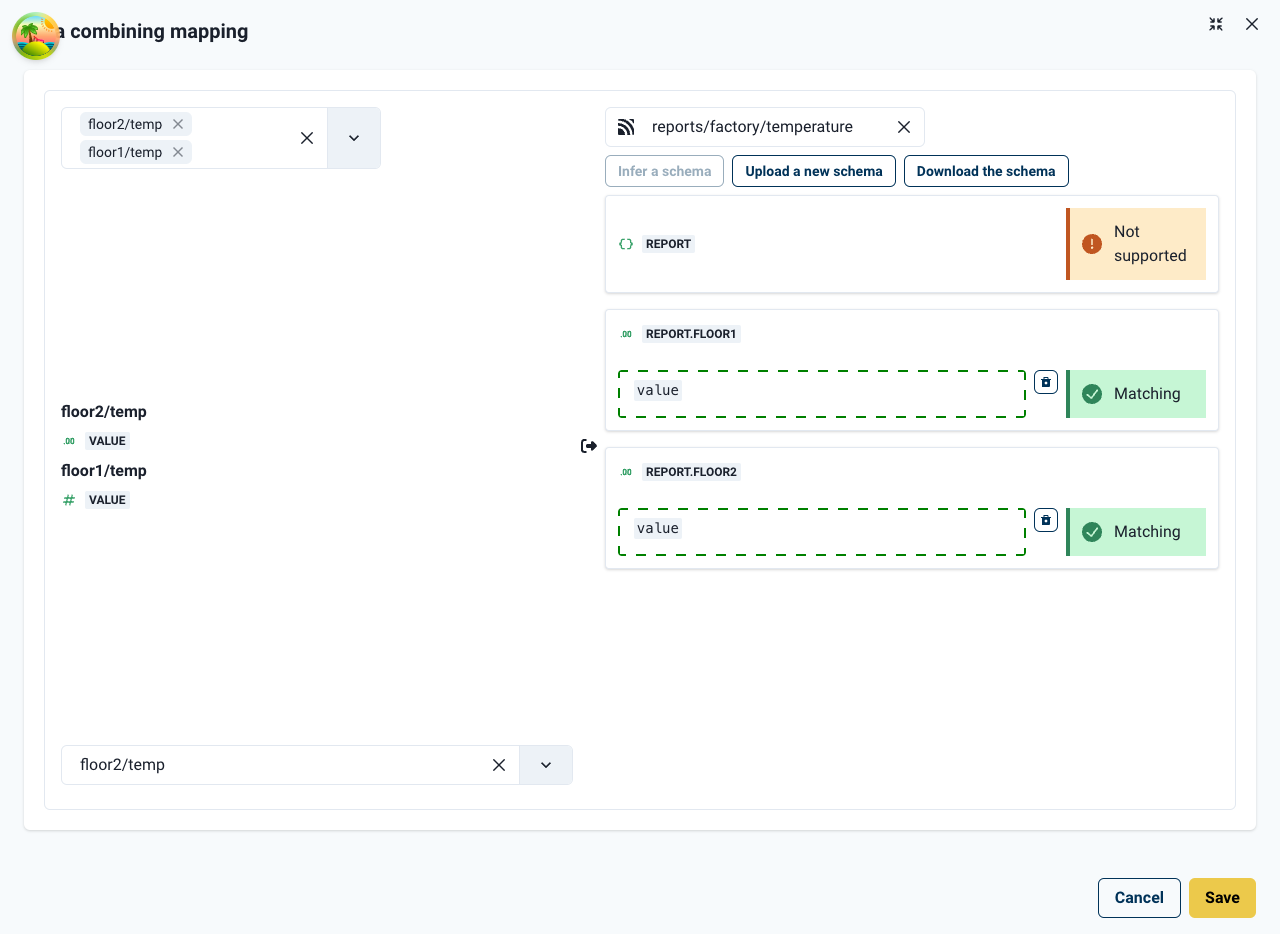
Once our desired data properties are mapped, the combiner mapping can be saved and the combiner updated. The creation of the new northbound data combination will be acknowledged (see below).
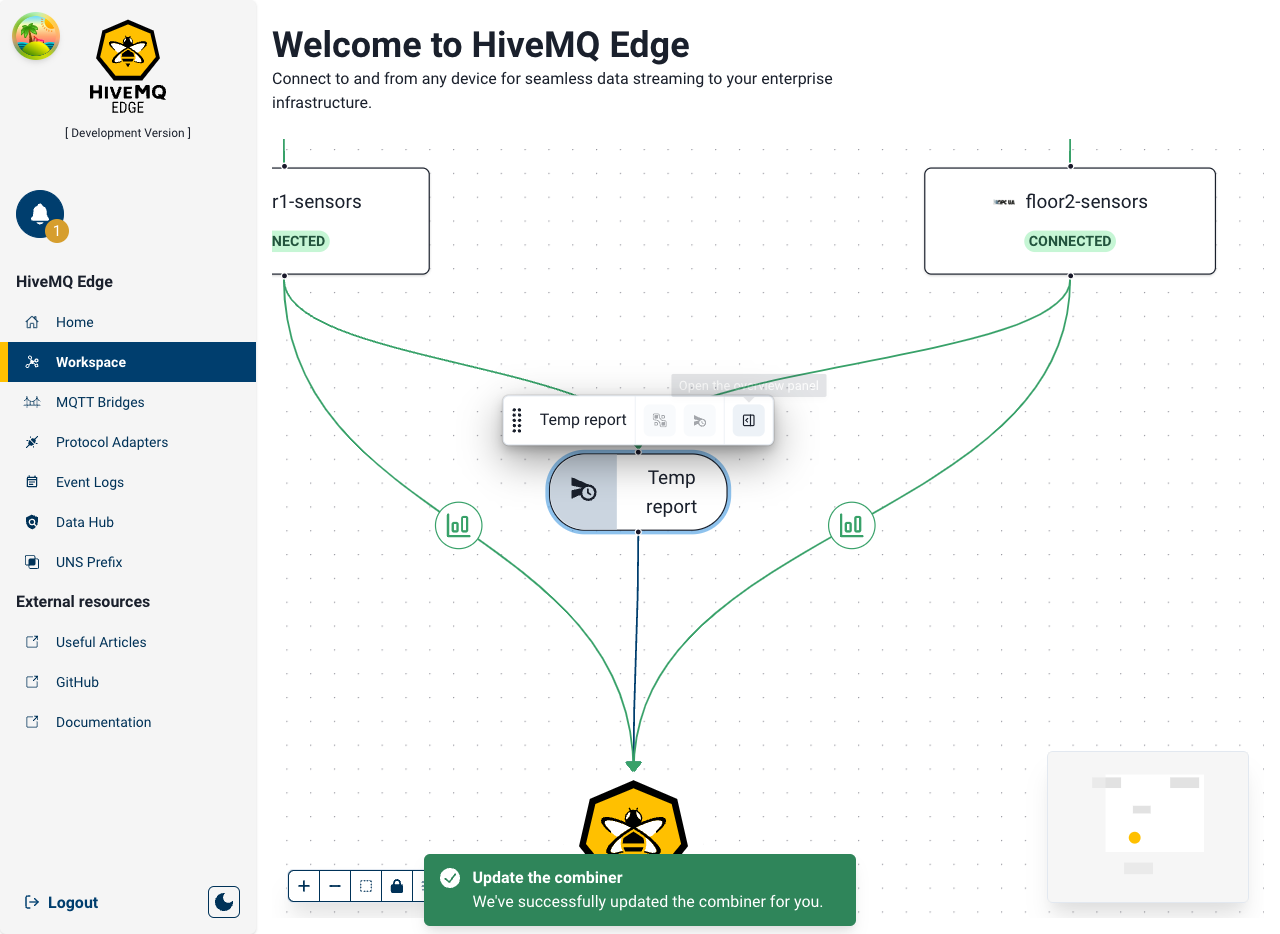
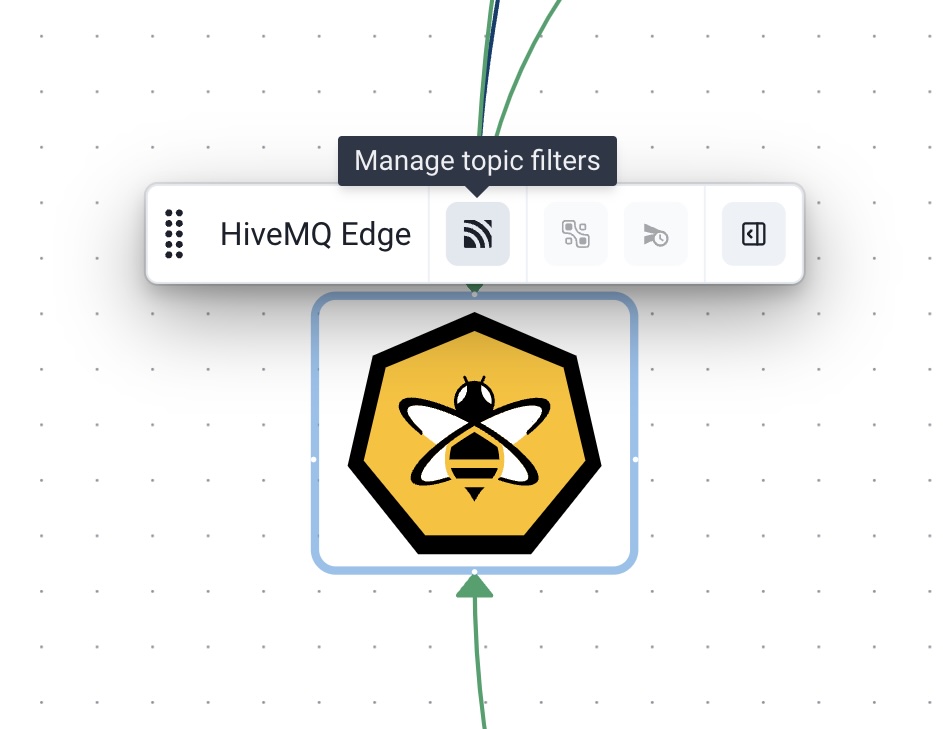
For now only OPC-UA tags are directly supported with more protocols to follow, if you want to combine other data sources you can generate a topic filter for your existing mappings via the Manage topic filters menu on the Edge node in the Workspace, and combine topic filters instead of tags.
How it helps
Enabling the mixing of data sources together in new topics to publish northbound can enable contextualisation of data closest to the source and not further up the operational stack, which reduces latency and increases efficiency of data and unlock real time insights based on operational data being collected at the edge.
Data Hub with Stateful Transformation
Data Hub’s existing transformation capability allows you to transform incoming MQTT messages to compute additional information. For example: correct the format of the data, or split messages into smaller messages. Today, we announce that Data Hub transformations now support client-connection state to enable stateful transformation which can unlock many use cases where in-flight transformations are necessary.
How it works
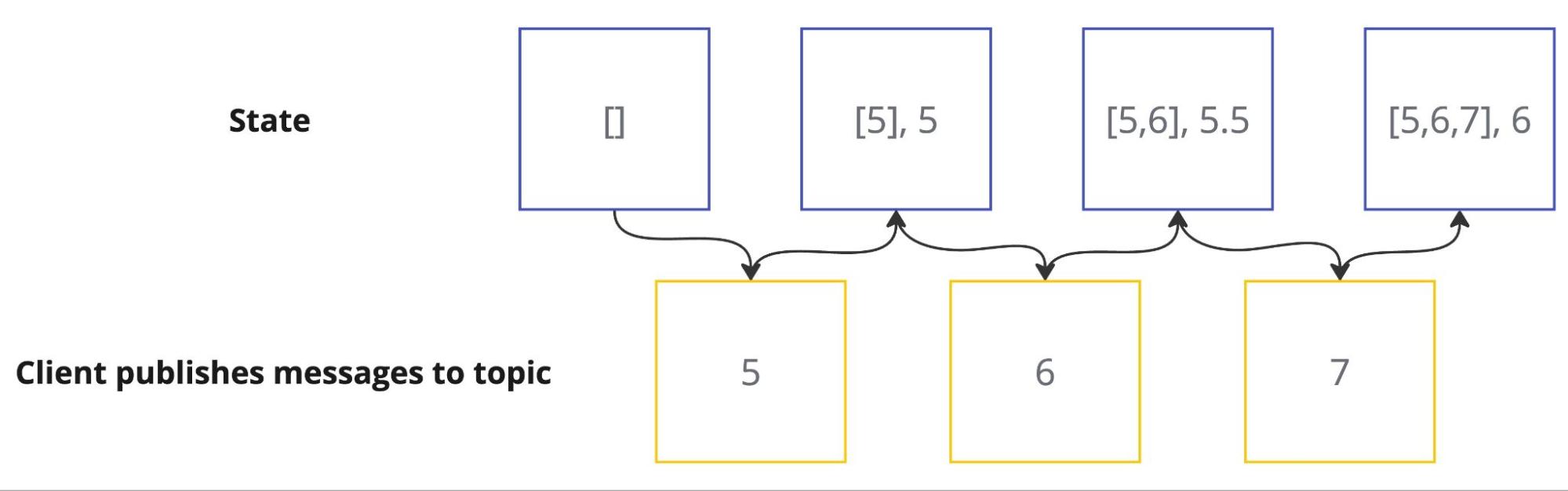
Every MQTT client which is governed by a data-policy and a stateful transformation script, initializes a state with default values and a user-defined data structure. An example describes the general mechanics of the feature.
Suppose a client publishes temperature values to the broker on a particular topic. Moreover there is a transformation script that collects the last 10 values and computes an average value of these values. The diagram below illustrates the state progressing when a client sends temperature values to a topic over time. On the top, you can see the state over time, which is initialized by [] (empty array). Once the client publishes the first message with a temperature of 5, it is added to the last 10 values of temperature, which results in an array of [5] and an average value of 5 being published. With more data being sent to the broker, eventually, more temperature values are added to the array, and the state is updated for the average output of every message.
In a Data Hub transformation script, you can create a state for a client connection using the function addClientConnectionState.
function init(initContext) {
initContext.addClientConnectionState('temperatureStats',
{ previousValues: [], average: 0 }
);
}
function transform(publish, context) {
const temperatureState = context.clientConnectionStates['temperatureStats'];
const temperatureStats = temperatureState.get();
const N = 10;
temperatureStats.previousValues.unshift(publish.payload.temperature);
temperatureStats.previousValues = temperatureStats.previousValues.slice(0, N);
temperatureStats.average = temperatureStats.previousValues.reduce((a, b) => a + b) / temperatureStats.previousValues.length;
temperatureState.set(temperatureStats);
publish.payload.average = temperatureStats.average;
return publish;
}
How it helps
The Data Hub Stateful Transformation engine enables you to perform complex transformations on Edge nearest the source of the data and without the need for local database storage to hold stateful data, this ensures that data is being normalised on the fly which increases your data processing efficiency and ensures processed data is being streamed from the edge to your HQ broker ready for critical business use
Helm Chart Improvements
We’ve also made some further improvements to our Helm capabilities in Edge as detailed below.
Data Hub Enhancements
- Data Hub can now be activated directly via Helm.
- You can preload Data Hub with a preset file, including built-in schema validation.
- Data Combiners can now be loaded seamlessly through Helm for easier configuration.
Additional Improvements
- Persistence can now be enabled via Helm, ensuring durability for messages and stateful transformations.
- Define volume claims directly in the Helm chart for better storage management.
- Admin credentials are now configurable via Helm, improving security and flexibility.
- The security context can be fully customized, providing better control over permissions and execution environments.
Issues resolved
- Running Edge behind a Proxy/LoadBalancer is now possible due to a fix in the redirect logic.
Get Started Today
Get started by running
docker run --name hivemq-edge --pull=always -d -p 1883:1883 -p 8080:8080 hivemq/hivemq-edge
or clone our repository
git clone git@github.com:hivemq/hivemq-edge.git
HiveMQ Team
The HiveMQ team loves writing about MQTT, Sparkplug, Industrial IoT, protocols, how to deploy our platform, and more. We focus on industries ranging from energy, to transportation and logistics, to automotive manufacturing. Our experts are here to help, contact us with any questions.

